关联规则概述
关联规则也是一种 无监督 学习方法。是一种 描述性 算法而非预测性。所揭示的关系可以被表示为 关联规则(asocciation rules)或 频繁项集(frequent itemset)。通常用于购物篮中商品购买关联的分析、点击流分析、推荐系统等。
关联规则可以表示为:X → Y (概率)
即,当X被购买(观察到)时,Y也会被购买(观察到)的概率。X为LHS,Y为RHS。
关联规则可以回答以下问题:
- 哪些产品可能会被一起购买?
- 与某客户相似的客户倾向于买什么产品?
- 对于已经购买某产品的客户,还可能查看或者购买什么其他类似的产品?
Apriori算法 是用于生产关联规则的最早的、最基本的算法。
Apriori算法
几个概念
- 项集:包含某种关系的一系列项目。可以是一次交易中一起购买的一系列商品,也可以是用户在单个会话中的点击流。
- k项集:包含k个项目的项集。通常用 \({\lbrace item_1, item_2, …, item_k \rbrace}\) 表示。
- 支持度(support):给定一个项集L,L的支持度是所有交易中包含L的交易的比例。(\(\frac{包含L的交易}{所有交易}\))
- 频繁项集(frequent itemset):出现足够频繁的项集。足够频繁 由 最小支持度(minimum support) 定义。即用支持度作为指标,对所有项集进行划分,支持度大于最小支持度的项集被定义为频繁项集。
- Apriori属性(向下封闭性):如果一个项集被认为是频繁的,那么该频繁项集的任何子集也必定是频繁的。反过来,如果一个项集被认为是不频繁的,那么包含它的项集必定也是不频繁的。Apriori属性是Apriori算法的基础。
算法流程
采取一种自下而上的迭代方式。先找到\(k = 1\)的频繁项集,逐步向上找到指定\(k\)的频繁项集。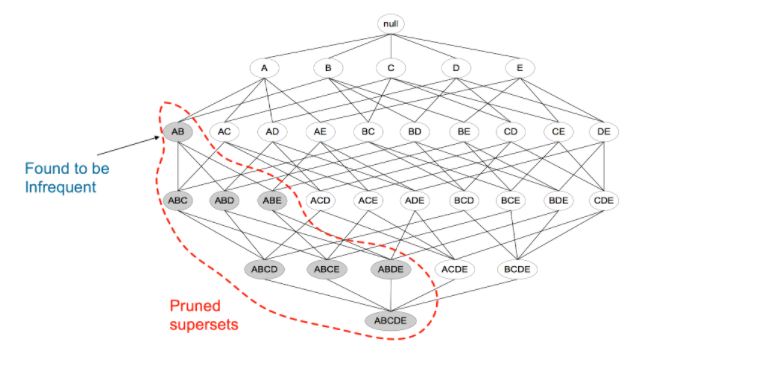
\(C_k\)表示候选k项集,\(L_k\)表示在\(C_k\)中通过最小支持度筛选的k项集。
- 从交易购物篮中确定所有可能项,即1项集\(C_1\)
- 计算\(C_1\)的支持度,丢弃(剪枝)支持度小于最小支持度的项,得到\(L_1\)
- 由\(L_k\) 生成 \(C_{k+1}\)
- 计算\(C_{k+1}\)的支持度,丢弃支持度小于最小支持度的项,得到\(L_{k+1}\),k ++。
- 循环3、4步骤,直到\(L_k\) 为空(不存在大于最小支持度的k项集)或者k达到预设值(频繁k项集中的项数目已经足够大)时停止循环。
- 最终得到的频繁项集为\(L_1 \cup L_2 \cup … \cup L_k\)。
每一个频繁项集中任意取出子集,两两有序组合,可以构造出 候选规则。如频繁项集{milk, eggs}可以表示出候选规则{milk} → {eggs},{eggs} → {milk}
算法优化
Apriori算法通过只检查满足了最小支持度的项集,可以减少一定计算量。但是在该算法中,对于每一个级别项集的支持度,都需要扫描整个数据库以获得结果。可以采用以下方法提高效率:
- 数据库分区:交易数据库中任何可能的频繁项集必须在至少一个分区中出现,才被认为是“频繁”的。
- 采样:先用较低支持度阈值提取数据集的一个子集,然后使用子集来执行关联规则挖掘。
- 交易压缩:不包含频繁k项集的交易在后续的扫描中是无用的,可以忽略。
- 基于哈希的项集计数:如果一个k项集相应的哈希桶计数低于某一阈值,则该k项集不可能是频繁的。
上一段话摘自《数据科学与大数据分析》书籍原文,其中“基于哈希的项集计数”没怎么看懂…网上检索了一些信息后,发现其实是建了一棵哈希树?等弄清楚了再补上这一部分。
评估候选规则
度量指标
- 置信度(confidence):同时包含X和Y的交易与只包含X的交易的比例,(条件概率)。
$$Confidence(X \to Y) = \frac{Support(X \land Y)}{Support(X)}$$
可以设定最小置信度阈值,用于筛选置信度较高的关联规则。支持度 和 置信度 是Apriori算法中最为常见和重要的度量方法。
然而置信度只考虑先导(X)和共存(XY),没有单独考虑规则的后继(Y)。这种度量方式会导致一个后果:就算X和Y独立分布,如果Y的出现频次很高,X → Y的关联规则就会有很高的置信度,但是Y的出现并不依赖于X。
因此,引入提升率和杠杆率度量关联规则。这两个量都是X和Y 相关性 的度量。
提升度(lift):测量当X与Y独立分布时,X和Y一起出现的次数比预期多多少。
$$Lift(X \to Y) = \frac{Support(X \land Y)}{Support(X) * Support(Y)}$$
X和Y独立分布时,值为1,提升度越大,表示X和Y的 关联性越强。杠杆率:与提升度类似,但用 差 表示(而不是 比例)。
$$Confidence(X \to Y) = {Support(X \land Y)} - {Support(X)}$$
X和Y独立分布时,值为0,杠杆率越大,表示X和Y的 关联性越强。
主观参数
即使有较高的置信度和支持度,有的规则也是想当然的、无意义的。比如{paper} → {pencil}并不是有价值的关联规则,因为并不能揭示任何非预期的盈利行为。
而像{diaper} → {beer}这样的规则,只要满足了 最小支持度和最小置信度(就算没那么高),因为“啤酒和尿布”的组合是令人意外的,就可以在主观上认为是有价值的。
R的实现
关联规则和频繁项集处理算法包:arules
对应的可视化包:arulesViz
arules包中定义了一个叫做 transactions 的类
数据解释
使用arules包中的Groceries数据集做示例,该数据集是一个transactions类,transactions类数据包含三列信息:
- transactionInfo: 一个数据帧,其向量长度与交易的数量相同。
- itemInfo:储存商品标签的数据帧。
- data:二进制关联矩阵,表示每次交易中出现哪些商品标签。
Groceries数据中,itemInfo标记了所有商品标签,以及每个标签的父级类别(level2是labels的父级类别,level1是level2的父级类别)1
2#显示前20个itemInfo
Groceries@itemInfo[1:20, ]

data是二进制矩阵,1意味着该交易中存在对应商品。每一行为一次交易,每一列对应一个item。1
Groceries@data
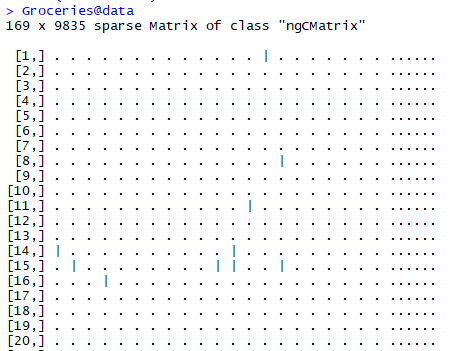
Groceries数据集中没有transactionInfo数据,但事实上,transactionInfo是最常见的数据集,每一行为一次交易,包含交易购买的item,长度不固定。itemInfo可以看做从transactionInfo中获得的所有item,data则是根据transactionInfo和itemInfo,将交易数据转换为长度固定的二进制矩阵中的行。
arules::apriori函数
arules包中的apriori函数用于执行apriori算法,可以生成频繁项集或是关联规则。
生成频繁项集
1 | itemsets = apriori(Groceries, parameter = list(minlen = 1, maxlen = 4, support = 0.02, target = "frequent itemsets")) |
minlen 设置频繁项集的最小向量长度,maxlen 设置最大向量长度(即k值,不设置则默认迭代到频繁k项集 空 为止,support 设置最小支持度)
target 指定结果,可以是 频繁项集(frequent itemsets)也可以是 规则(rules)等等。具体查看 APparameter。
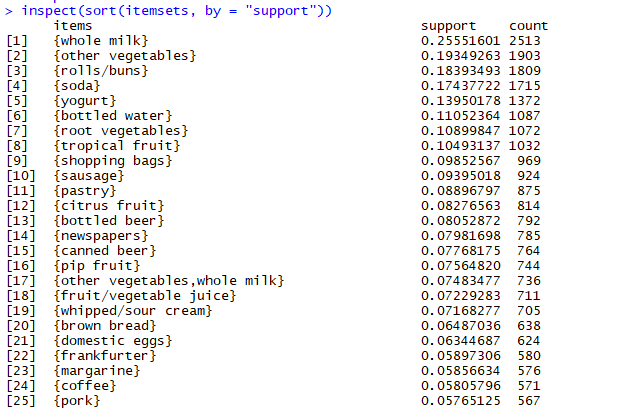
使用inspect函数检查频繁项集1
inspect(sort(itemsets, by = "support"))
生成规则
1 | rules = apriori(Groceries, parameter = list(support = 0.001, confidence = 0.6, target = "rules")) |
target 指定为”rules“,confidence 设置最小置信度。
使用inspect函数检查规则1
inspect(sort(rules[1:20], by = "support"))
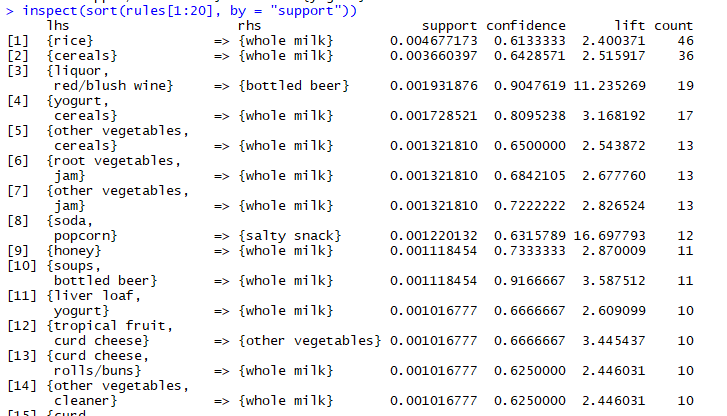
规则的可视化
1 | plot(rules) |
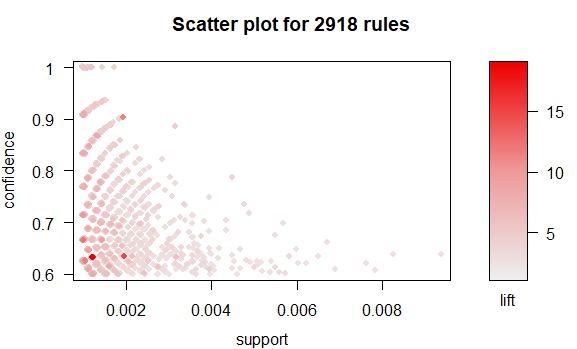
其中,x轴表示支持度,y轴表示置信度,颜色深浅表示提升度。可以发现,最高的提升度发生在一个较低支持度和较低置信度的位置。
参考资料
- 《数据科学与大数据分析》第5章:关联规则