聚类概述
聚类指的是,通过 无监督 技术对相似的数据对象进行分组形成 簇。簇内相似,簇外相异。所谓“无监督”,指的是不需要人为标注簇的特征,特征在形成簇后才试图解释。聚类不用来做预测,仅仅根据对象属性来查找对象之间的相似性。聚类通常作为分类的第一步,作为更深入的分析或决策过程的前奏。
根据不同方法思想,总结k-means聚类、层次聚类、密度聚类。
k-means聚类
输入:n个可衡量属性的对象、指定期望输出的簇的个数k
输出:满足方差最小标准的k个簇
k-means基于对象与 簇中心 的相似度(相似度由 距离 衡量),将对象分成k个簇。采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。k-means算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标。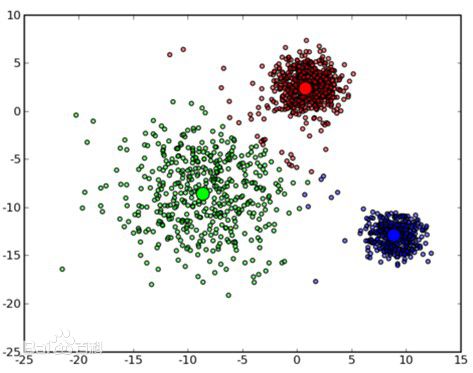
几个概念
- 簇中心:每个簇中对象的n维属性向量的算术平均值。
- 质心(centroid):簇中心所在的点。(不知道自己的理解对不对,感觉簇中心跟质心指的概念相似。质心可以是簇中最接近簇中心的对象的位置(像是样本点的中位数),也可以不与簇中任何对象的位置相同(像是样本点的均值))
- 距离:在k-means算法中距离一般指的是欧氏距离。
方法流程
- 选定k个质心的初始猜测值(随机选取)。
- 对每个点,分别计算它到k个质心的距离,将该点分配给距离最近的质心所在的簇。于是得到k个簇。
- 对于每个簇,重新计算簇中心作为新的质心。
- 迭代步骤2和3,直到质心不改变,或者质心和所分配的点在两个相邻迭代间来回振荡(存在到两个质心的距离相等的点时),算法收敛。
一些考量
诊断
直观上地,聚类结果可以采用可视化的诊断方式,考虑:
- 聚类之间是否较好地相互分离?
- 是否存在只有几个点的簇?
- 是否有靠得很近的质心?
如果更多的簇没有形成更好的簇之间的区分,那么 更少 的簇应该是更好的选择。
确定k值
k-means聚类算法中k值需要人为指定,选取不同的k值对聚类的最终效果产生较大影响。有必要找到一个衡量聚类结果的量化指标。
使用组内平方和(WSS)的启发式算法
WSS(Within Sum of Square),想要通过点与其所在簇的质心间的距离,来衡量聚类结果的好坏。
WSS = 所有 点到点所在簇的质心距离 的平方和
如果这些点相对靠近它们各自的质心,那么WSS将相对较小,聚类结果较好。如果k+1聚类没有 显著降低 k聚类中的WSS值,那么增加一个簇可能意义不大。
可以通过绘制WSS值-k值曲线的方式寻找最佳k值,曲线样子类似于反比例函数曲线,选定WSS显著较小后的k值。
轮廓系数
轮廓系数(Silhouette Coefficient),是一种相对成熟的聚类效果评价方式。最早由 Peter J. Rousseeuw 在 1986 提出。它综合考虑了 组内的凝聚度 和 组间的分离度。以此来判断聚类的优良性。取值在-1到+1之间,值越大表示聚类效果越好。
实际应用时的事项选择
- 对象属性: 尽可能地减少属性的数量。根据属性间的相关性筛选属性,或者将多个属性组合到一个属性中
- 属性计量单位:属性计量单位的选择会改变属性的值,在距离计算中会得到不同的距离(即欧式距离的计算受到量纲的影响),尤其是在与别的属性一起计算距离的时候,某个属性计量单位的改变很有可能会改变距离计算的支配属性。
例如:(年龄,身高),年龄都已年计,身高分别以米和厘米计,计算距离时,(年,米)的单位组合由于年龄一定比身高大很多,距离受到年龄支配。 - 属性值调整:与2的原因相同,由于每个属性值没有统一的度量标准,值大的属性很容易支配距离计算结果。所以在计算距离前需要将属性值 标准化。将每种属性除以该属性的标准差,使得新属性值的标准差为1。
还可能需要对倾斜数据做取对数处理,使得1000元收入到10000元的距离与10000到100000的距离一样。 - 初始质心敏感:由于初始质心的选择是随机的,就算指定同一个k值,最后的到的结果也不尽相同。故需要对每个k值进行多次聚类计算。
- 选择不同方法计算距离:根据不同的数据集,选择最能反映数据特征的方法计算数据间的距离。距离可以是余弦相似度(cosine similarity)、曼哈顿距离(Manhattan distance)、马氏距离(Mahalanobis distance)等等。
k-means算法能很容易地应用到有距离概念的数值型数据中,但不能很好地处理分类变量。分类变量可以采用k-mode算法。
k-means算法快速简单,就算数据规模较大也有较好的效率表现。但是不适合于非球形的数据(期望的簇不是球形),非球形数据的聚类可以采用密度聚类算法。
R的实现
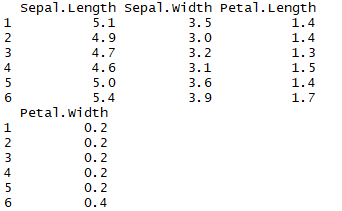
以iris数据集中的4个数值变量为例:1
2data = iris[, -5]
head(data)
标准化数据
1 | means = sapply(data, mean) |
kmeans函数
其中centers指期望得到的簇数量(即k值),nstart值对于当前k值进行多少次重复计算。
kmeans函数缺省使用欧氏距离,簇中心为样本点的均值。1
2clusterModel = kmeans(dataScale, centers = 3, nstart = 10)
clusterModel
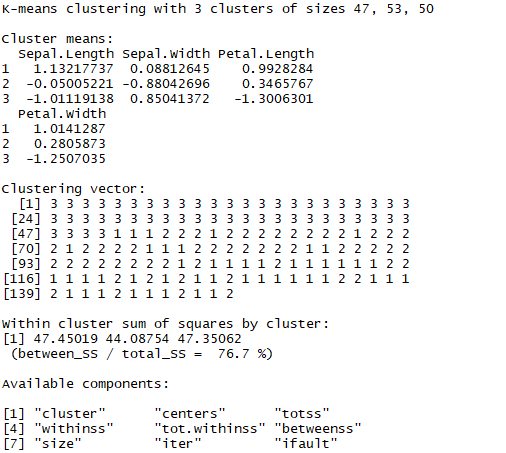
结果显示内容如下:
- 簇均值的位置
- 聚类向量,定义每个样本所属的聚类簇序号
- 每个簇的WSS
- 所有k均值聚类的相关数据
cluster::pam函数
簇中心为样本中的一个点,可以指定不同距离计算方式。1
2
3library(cluster)
clusterModel2 = pam(dataScale, k = 3, metric = "Mahalanobis")
clusterModel2
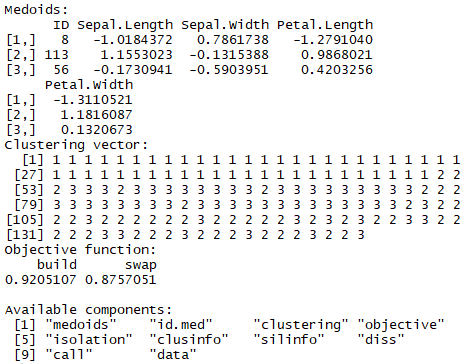
帮助获得最优k值的函数
- rinds::bestCluster:输入数据和一个整数向量,可以自动输出轮廓细数最优的聚类数。
- fpc::kmeansruns:可以根据不同聚类数的求得各自的轮廓系数。
层次聚类(系统聚类)
最后得到的结果是一棵聚类树,需要多少个聚类从树中取出。
方法流程
- 首先将每个样本单独作为一类
- 将不同类之间距离最近的类进行合并
- 重新计算类间距离
- 循环操作步骤2、3,直到所有样本归为一类
可以采用不同距离作为类间距离的计算标准:最短距离法、最长距离法、类平均法、重心法、中间聚类法、离差平方和法。
R的实现
stats::hclust函数
输入为距离矩阵,不需要原始数据,同样需要标准化数据。
重要参数包括:
- 样本间的距离矩阵
- 计算类间距离的方法。
采用上文标准化后的数据dataScale为例。1
2
3
4
5
6
7
8
9#计算距离矩阵
Dist = dist(dataScale, method = "euclidean")
#得到hclust层次聚类结果树
clusterModel3 = hclust(Dist, method = "ward")
#从结果树中获得k = 3的聚类结果
result = cutree(clusterModel3, k = 3)
result

可以发现最后取出的结果同样是,对于每个样本,给出它所在的簇序列号。
对于层次聚类结果树,可以采用plot绘图。1
plot(clusterModel3)
结果如下:
密度聚类
可以帮助识别非球形的簇。寻找那些被低密度区域所分离的高密度区域。
典型的密度聚类算法包括DBSCAN算法。
DBSCAN算法
该算法将所有点分为三类:
- 核心点:如果某个点的邻域内的点个数超过某个阈值,则该点为核心点。(邻域由半径参数eps决定,阈值由MiniPts参数决定)
- 边界点:如果某个点不是核心点,但它落在核心点的邻域内,则该点为边界点。
- 噪声点:既不是核心点也不是边界点的点。
算法先将所有的点标记为以上三类。然后将任意两个距离小于eps的核心点归为同一簇。任何与核心点足够近的边界点也放到与之相同的簇中。
在R中可以采用fpc::dbscan函数实现
优缺点
- 优点:可以对抗噪声并且处理任意形状和大小的簇。
- 缺点:稀疏点集合中的密度很难定义,效果较差。算法对于计算资源的消耗很大。
参考资料
- 《数据科学与大数据分析》第4章:聚类
- 《数据科学中的R语言》第8章 第2节:聚类